
Hola amigos soy Fare9, y después de un largo periodo en el que he estado liado con exámenes, vuelvo con el cursillo de exploiting, hoy veremos una técnica muy interesante llamada "Return to Libc", pero antes aquí una cabecera que he hecho con el paint:

Aquí dejo los enlaces a los anteriores "de 0 a exploiting" para quien no nos haya seguido:
1. De 0 a exploiting I
2. De 0 a exploiting II
3. De 0 a exploiting III
4. De 0 a exploiting IV
5. De 0 a exploiting V
6. De 0 a exploiting VI
Además, sabéis que podéis seguirme en twitter: Fare9 twitter
Cualquier duda intentaré responder lo antes posible por aquí.
Pero como siempre, aquí los preparativos:

Hoy, NOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO. La técnica que veremos hoy, nos va a quitar que tengamos que desactivar una de las medidas de seguridad así que hoy sólo nos quedaremos con una parte:
###############################################
Desactivar la aleatoriedad en las direcciones de la pila, para ello debeis ejecutar el comando (como root):
echo 0 > /proc/sys/kernel/randomize_va_space
###### ACTUALIZACIÓN
Recompilando los ejecutables en la última versión de Ubuntu, me activa el stack protector por defecto (conocido como canary value), por tanto para compilar, podéis quitar las opciones de -g -z execstack.
Podéis utilizar esto para compilar:
gcc -fno-stack-protector codigo.c -o programa
###############################################
La teoría de por qué hoy no compilaremos raroraroraro
Una medida de protección contra los ataques de stack overflow, es el marcado de páginas de memoria como no "ejecutables", en caso de meter un payload en la pila e intentar ejecutarla cuando tenemos esta protección resulta inutil. Esto se hace con un bit conocido como NX, este bit es dependiente del hardware, y Linux es capaz de emularlo con PaX, ya que las arquitecturas ARM y IA32 no lo implementan de por sí.
Return to Libc
esta es una técnica útil cuando se nos da este problema, que llegamos a un sistema y no podemos meter un payload en la pila. De momento vamos a decir que lo que veremos hoy será una explotación en local y por eso aplicaremos varias técnicas hoy.
Antes de nada necesitamos ver que código vulnerable usaremos:

En return to libc lo que haremos será ejecutar directamente un método de la librería Libc (a que no os lo esperabais), para ello sobreescribiremos la dirección de EIP que es guardada cuando se ejecuta una función. La función que ejecutaremos será una del estilo system(), execve(), execvp()... Tendremos que ver entonces como conseguir hacerlo.
A la hora de montar nuestro exploit tendremos que ver bien como funciona la pila y sobre todo las llamadas a las funciones, volvamos a recordar un dibujo:
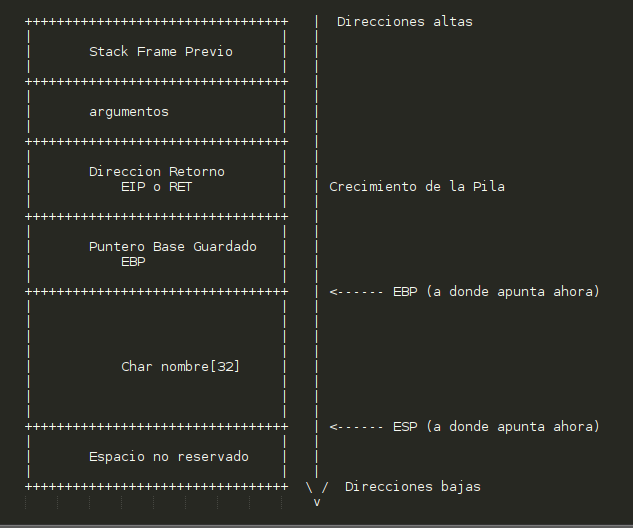
A la hora de llamar a una función, se pasaban los argumentos, se guardaba el valor de EIP y finalmente se montaba toda la función, con esta técnica haremos algo parecido, pondremos el puntero a la función a ejecutar, el valor de su propio EIP (luego veremos que usaremos) y los argumentos, en este caso un puntero a una cadena /bin/sh.
Aún tendremos que desactivar ASLR para tener en cada ejecución las direcciones en el mismo sitio y también necesitamos saber cuantos bytes podemos escribir antes de sobreescribir EIP.
Esta técnica nos servirá para ver que algunas medidas de seguridad, no son tan seguras:

Primero ejecutaremos el programa con unos argumentos más o menos normales, para ver su ejecución:

Como se puede ver, nada malo ha pasado, se ha ejecutado el programa sin ninguna dificultad.
Ahora vamos a intentar petar el programa, para ello tiraremos de una cadena enorme en python:

Ahora si, hemos metido 1024 Aes, y qué ha pasado?
En el siguiente video en el segundo mostrado tendréis la respuesta: https://youtu.be/k7xCUbgzT9o?t=7
(Más tecnicamente es debido a un abuso de frame pointer en la función strcpy)
Necesitamos entonces saber en que momento pasó lo que dice el video, para ello calcularemos el número de bytes metidos antes de petar el programa
Obtención del número de bytes hasta sobreescribir EIP
para esta tarea, usaremos a nuestro gran amigo edb debugger, con el cual necesitamos ver el lugar donde nuestro programa copia el argumento con strcpy, y luego el sitio donde se guarda el EIP de retorno.
Ejecutamos entonces edb debugger con una cadena reconocible como el segundo argumento:

Tenemos que en memoria se copiará la cadena Fare9 (ajam, ajam, egocéntrico, ajam, ajam), a la hora de abrir edb, para ir a la función principal pulsaremos F9 (ajam, ajam que coincidencia).

Tendremos algo así, ahora iremos ejecutando con F7 (ya que queremos meternos en la función que sabemos tiene la vulnerabilidad).

Llegamos a algo así, vemos abajo a la derecha (el stack), los argumentos pasados a la función, y en cuanto pulsemos F7 de nuevo entraremos a la función:

La función es algo así, además si miramos abajo a la derecha, vemos donde se guarda el valor de EIP, esta es la dirección bfff:f3fc. Necesitamos llegar a la dirección donde se guarda la cadena (el buffer), vamos ejecutando hasta casi llegar a strcpy (sin ejecutarlo):

Aquí tenemos los argumentos pasados a strcpy, el primer argumento es el buffer donde se guardará la cadena, bfff:f1f0.
Ahora podemos calcular la distancia entre el buffer que usa strcpy y el sitio donde se guarda EIP, para saber el máximo número de bytes que tenemos antes de sobreescribir ese valor:
bfff:f3fc - bfff:f1f0 = (nos cargamos bfff ya que queda a 0, las otras f más de lo mismo y nos queda) 20c = 254 en decimal
Por tanto tenemos ya un dato.
Número de bytes antes de sobreescribir EIP = 254.
Ahora calcularemos el puntero a system, además como dijimos después de system meteremos un valor que será el EIP de system, en el cual meteremos por ejemplo una función "exit", así evitaremos que el programa al volver de la ejecución system(/bin/sh) pete y deje logs que nos descubran, para buscar los punteros a las dos funciones sigamos:
Puntero a las funciones system y exit
Esto será facilito y para toda la familia, además de rápido e indoloro (de momento). Usaremos el debugger gdb, y ejecutaremos el programa, una vez ejecutado buscaremos los punteros, que como ASLR lo hemos desactivado, pues siempre serán los mismos:

Tenemos ya los dos punteros, a uno le llamaremos en un alarde de originalidad &system y al otro &exit (recordando nuestras clases de C, & era la dirección de memoria de algo, un puntero).
&system = 0xb7e38b30
&exit = 0xb7e2c7e0
Ahora finalmente necesitamos un puntero a una cadena /bin/sh, para eso como dije estamos en local, y lo que podemos hacer es crear una variable de shell y obtener su dirección, igual esto será algo fácil e iremos paso por paso.
Puntero a cadena /bin/sh
Lo primero que haremos será crear la variable de shell, esta debe ser global por tanto usaremos export:


Aquí tenemos una dirección bffff651 el principio de la cadena SHELL2=/bin/sh, pero necesitamos avanzar hasta un byte menos que la cadena que buscamos (en este caso el '='), vamos contando bffff651 apunta a S, ...52 a H, ....53 a E,........57 a =, bien entonces nos quedaremos con bfff:f657 ya que luego vendrá nuestra rica y preciada cadena:

&/bin/sh = 0xbffff657
ACTUALIZACIÓN###################################
para los que no quieran contar, o les pueda dar fallos, le voy a dejar el código de un código en C, que al compilar debemos ejecutarlo indicando la variable SHELL2 y el nombre del programa (en mi caso ret_to_libc), así obtendremos la dirección directamente: (Código Linux Exploiting capítulo 4)


Con este programa conseguis directamente la dirección exactamente sin contar.
Finalmente queda la explotación de la vulnerabilidad
Recopilación de datos y explotación de la vulnerabilidad
Número de bytes para llegar a EIP = 254
&system = 0xb7e38b30
&exit = 0xb7e2c7e0
&/bin/sh = 0xbffff657
"En 2017 cuatro de los números usados para la explotación de un programa, fueron borrados de memoria por una explotación que no cometieron. No tardaron en encontrar otra forma de ejecución en memoria. Hoy, buscados todavía por políticas de ejecución seguras, sobreviven como payloads de fortuna. Si tiene usted algún zero day, y se los encuentra, quizá pueda utilizarlos...", Fare9 ,desvarío mental.
Bien usaremos a nuestro gran python para montar una cadena, como ya dije tenemos que reemplazaremos la dirección de vuelta EIP por el puntero a system, este tendrá su propio EIP en memoria que le sigue, el cual se usará cuando se salga de system, este dijimos que era exit, y siguiendo a exit tendremos los argumentos, usaremos un dibujo para entenderlo mejor:
 Gracias a tí Fare9, mi vida es más fácil =)...
Gracias a tí Fare9, mi vida es más fácil =)...
Bueno el dibujo lo deja más o menos claro, rellenamos el buffer con un montón de Aes, y al llegar a eip metemos el puntero a system, seguido tenemos un puntero de retorno, en este caso decidimos exit y finalmente los argumentos, en este caso puntero a /bin/sh, podríamos poner por ejemplo un puntero a ls, cp, cat /etc/shadow ....
Creemos con la ayuda de nuestro quiero python, la explotación:
 Vamos a ver que ha pasado, en la ejecución:
Vamos a ver que ha pasado, en la ejecución:

EXPLOTADOOOOOOOOOOOOOOOOOOOOOOOOOOOOO:

Veamos que pasa si en lugar de poner un puntero a exit, no ponemos algo razonable, algo como..."\xe2\xc7\xe2\xb7" (4 bytes). Sólo hemos modificado el último byte en lugar de e0, e2:
 Como dije, violación de segmento, esto crea logs, alerta a todo el mundo...
Como dije, violación de segmento, esto crea logs, alerta a todo el mundo...
Hoy hemos aprendido que aunque no nos permitan ejecutar código en la pila, nosotros podemos seguir ejecutando código, bypasseando la medida de seguridad que marca la memoria de pila como no ejecutable, para ello hemos redirigido el código a una zona de memoria ejecutable como son las librerías.
--------------------------------------------------------FIN
Para el próximo post veremos como encadenar funciones con una técnica llamada ROP, la cual igual veremos más adelante de forma más avanzada, así que será una introducción para que nuestra mente se vaya haciendo a ello:

Pues hasta el próximo de 0 a exploiting.

Aquí dejo los enlaces a los anteriores "de 0 a exploiting" para quien no nos haya seguido:
1. De 0 a exploiting I
2. De 0 a exploiting II
3. De 0 a exploiting III
4. De 0 a exploiting IV
5. De 0 a exploiting V
6. De 0 a exploiting VI
Además, sabéis que podéis seguirme en twitter: Fare9 twitter
Cualquier duda intentaré responder lo antes posible por aquí.
Pero como siempre, aquí los preparativos:
Hoy, NOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO. La técnica que veremos hoy, nos va a quitar que tengamos que desactivar una de las medidas de seguridad así que hoy sólo nos quedaremos con una parte:
###############################################
Desactivar la aleatoriedad en las direcciones de la pila, para ello debeis ejecutar el comando (como root):
echo 0 > /proc/sys/kernel/randomize_va_space
###### ACTUALIZACIÓN
Recompilando los ejecutables en la última versión de Ubuntu, me activa el stack protector por defecto (conocido como canary value), por tanto para compilar, podéis quitar las opciones de -g -z execstack.
Podéis utilizar esto para compilar:
gcc -fno-stack-protector codigo.c -o programa
###############################################
La teoría de por qué hoy no compilaremos raroraroraro
Una medida de protección contra los ataques de stack overflow, es el marcado de páginas de memoria como no "ejecutables", en caso de meter un payload en la pila e intentar ejecutarla cuando tenemos esta protección resulta inutil. Esto se hace con un bit conocido como NX, este bit es dependiente del hardware, y Linux es capaz de emularlo con PaX, ya que las arquitecturas ARM y IA32 no lo implementan de por sí.
Return to Libc
esta es una técnica útil cuando se nos da este problema, que llegamos a un sistema y no podemos meter un payload en la pila. De momento vamos a decir que lo que veremos hoy será una explotación en local y por eso aplicaremos varias técnicas hoy.
Antes de nada necesitamos ver que código vulnerable usaremos:

En return to libc lo que haremos será ejecutar directamente un método de la librería Libc (a que no os lo esperabais), para ello sobreescribiremos la dirección de EIP que es guardada cuando se ejecuta una función. La función que ejecutaremos será una del estilo system(), execve(), execvp()... Tendremos que ver entonces como conseguir hacerlo.
A la hora de montar nuestro exploit tendremos que ver bien como funciona la pila y sobre todo las llamadas a las funciones, volvamos a recordar un dibujo:
A la hora de llamar a una función, se pasaban los argumentos, se guardaba el valor de EIP y finalmente se montaba toda la función, con esta técnica haremos algo parecido, pondremos el puntero a la función a ejecutar, el valor de su propio EIP (luego veremos que usaremos) y los argumentos, en este caso un puntero a una cadena /bin/sh.
Aún tendremos que desactivar ASLR para tener en cada ejecución las direcciones en el mismo sitio y también necesitamos saber cuantos bytes podemos escribir antes de sobreescribir EIP.
Esta técnica nos servirá para ver que algunas medidas de seguridad, no son tan seguras:

Primero ejecutaremos el programa con unos argumentos más o menos normales, para ver su ejecución:
Como se puede ver, nada malo ha pasado, se ha ejecutado el programa sin ninguna dificultad.
Ahora vamos a intentar petar el programa, para ello tiraremos de una cadena enorme en python:
Ahora si, hemos metido 1024 Aes, y qué ha pasado?
En el siguiente video en el segundo mostrado tendréis la respuesta: https://youtu.be/k7xCUbgzT9o?t=7
(Más tecnicamente es debido a un abuso de frame pointer en la función strcpy)
Necesitamos entonces saber en que momento pasó lo que dice el video, para ello calcularemos el número de bytes metidos antes de petar el programa
Obtención del número de bytes hasta sobreescribir EIP
para esta tarea, usaremos a nuestro gran amigo edb debugger, con el cual necesitamos ver el lugar donde nuestro programa copia el argumento con strcpy, y luego el sitio donde se guarda el EIP de retorno.
Ejecutamos entonces edb debugger con una cadena reconocible como el segundo argumento:
Tenemos que en memoria se copiará la cadena Fare9 (ajam, ajam, egocéntrico, ajam, ajam), a la hora de abrir edb, para ir a la función principal pulsaremos F9 (ajam, ajam que coincidencia).
Tendremos algo así, ahora iremos ejecutando con F7 (ya que queremos meternos en la función que sabemos tiene la vulnerabilidad).
Llegamos a algo así, vemos abajo a la derecha (el stack), los argumentos pasados a la función, y en cuanto pulsemos F7 de nuevo entraremos a la función:
La función es algo así, además si miramos abajo a la derecha, vemos donde se guarda el valor de EIP, esta es la dirección bfff:f3fc. Necesitamos llegar a la dirección donde se guarda la cadena (el buffer), vamos ejecutando hasta casi llegar a strcpy (sin ejecutarlo):
Aquí tenemos los argumentos pasados a strcpy, el primer argumento es el buffer donde se guardará la cadena, bfff:f1f0.
Ahora podemos calcular la distancia entre el buffer que usa strcpy y el sitio donde se guarda EIP, para saber el máximo número de bytes que tenemos antes de sobreescribir ese valor:
bfff:f3fc - bfff:f1f0 = (nos cargamos bfff ya que queda a 0, las otras f más de lo mismo y nos queda) 20c = 254 en decimal
Por tanto tenemos ya un dato.
Número de bytes antes de sobreescribir EIP = 254.
Ahora calcularemos el puntero a system, además como dijimos después de system meteremos un valor que será el EIP de system, en el cual meteremos por ejemplo una función "exit", así evitaremos que el programa al volver de la ejecución system(/bin/sh) pete y deje logs que nos descubran, para buscar los punteros a las dos funciones sigamos:
Puntero a las funciones system y exit
Esto será facilito y para toda la familia, además de rápido e indoloro (de momento). Usaremos el debugger gdb, y ejecutaremos el programa, una vez ejecutado buscaremos los punteros, que como ASLR lo hemos desactivado, pues siempre serán los mismos:
Tenemos ya los dos punteros, a uno le llamaremos en un alarde de originalidad &system y al otro &exit (recordando nuestras clases de C, & era la dirección de memoria de algo, un puntero).
&system = 0xb7e38b30
&exit = 0xb7e2c7e0
Ahora finalmente necesitamos un puntero a una cadena /bin/sh, para eso como dije estamos en local, y lo que podemos hacer es crear una variable de shell y obtener su dirección, igual esto será algo fácil e iremos paso por paso.
Puntero a cadena /bin/sh
Lo primero que haremos será crear la variable de shell, esta debe ser global por tanto usaremos export:

es sencillo, simplemente establecemos el nombre de la variable y un igual seguido de la cadena, con un echo podemos ver que todo ha salido bien. Como aprendí con uno de los videos de exploiting de Adastra, las variables de la shell se pasan todas a los programas al principio de su ejecución a la pila, por tanto con edb debugger, podemos arrancar nuestro programa y sin ejecutar nada obtener del stack una de las direcciones:


&/bin/sh = 0xbffff657
ACTUALIZACIÓN###################################
para los que no quieran contar, o les pueda dar fallos, le voy a dejar el código de un código en C, que al compilar debemos ejecutarlo indicando la variable SHELL2 y el nombre del programa (en mi caso ret_to_libc), así obtendremos la dirección directamente: (Código Linux Exploiting capítulo 4)

Con este programa conseguis directamente la dirección exactamente sin contar.
Finalmente queda la explotación de la vulnerabilidad
Recopilación de datos y explotación de la vulnerabilidad
Número de bytes para llegar a EIP = 254
&system = 0xb7e38b30
&exit = 0xb7e2c7e0
&/bin/sh = 0xbffff657
"En 2017 cuatro de los números usados para la explotación de un programa, fueron borrados de memoria por una explotación que no cometieron. No tardaron en encontrar otra forma de ejecución en memoria. Hoy, buscados todavía por políticas de ejecución seguras, sobreviven como payloads de fortuna. Si tiene usted algún zero day, y se los encuentra, quizá pueda utilizarlos...", Fare9 ,desvarío mental.
Bien usaremos a nuestro gran python para montar una cadena, como ya dije tenemos que reemplazaremos la dirección de vuelta EIP por el puntero a system, este tendrá su propio EIP en memoria que le sigue, el cual se usará cuando se salga de system, este dijimos que era exit, y siguiendo a exit tendremos los argumentos, usaremos un dibujo para entenderlo mejor:
Bueno el dibujo lo deja más o menos claro, rellenamos el buffer con un montón de Aes, y al llegar a eip metemos el puntero a system, seguido tenemos un puntero de retorno, en este caso decidimos exit y finalmente los argumentos, en este caso puntero a /bin/sh, podríamos poner por ejemplo un puntero a ls, cp, cat /etc/shadow ....
Creemos con la ayuda de nuestro quiero python, la explotación:

EXPLOTADOOOOOOOOOOOOOOOOOOOOOOOOOOOOO:


Hoy hemos aprendido que aunque no nos permitan ejecutar código en la pila, nosotros podemos seguir ejecutando código, bypasseando la medida de seguridad que marca la memoria de pila como no ejecutable, para ello hemos redirigido el código a una zona de memoria ejecutable como son las librerías.
--------------------------------------------------------FIN
Para el próximo post veremos como encadenar funciones con una técnica llamada ROP, la cual igual veremos más adelante de forma más avanzada, así que será una introducción para que nuestra mente se vaya haciendo a ello:

Pues hasta el próximo de 0 a exploiting.








