Buenas amigos hoy os traigo la segunda entrada de la serie "De 0 a exploiting", donde me obligo a leer un libro de exploting y traeros los conocimientos que obtengo (a mi manera).
Antes de nada, aquí vamos con los preparativos que diré siempre:
###############################################
Desactivar la aleatoriedad en las direcciones de la pila, para ello debeis ejecutar el comando (como root):
echo 0 > /proc/sys/kernel/randomize_va_space
Compilar (hoy si) con:
gcc -g -fno-stack-protector -z execstack codigo.c -o programa
###############################################
El otro día os dejé con una pregunta a partir de cuantas 'A's el programa empezaba a petar.
Vamos a explicar hoy el por qué peta (hoy toca algo de teoría) , pues es uno de los conceptos más importantes en el exploiting.
SOBREESCRIBIR EL REGISTRO EIP
Empecemos por el procesador, un elemento del ordenador el cual procesa datos e instrucciones, para finalmente realizar cálculos para lo cual se suele usar una ALU (Unidad Aritmético-Lógica). Los procesadores pueden guardar los datos en diferentes sitios, para ello pueden usar unas cosas llamadas "registros" los cuales tenemos algunos de proposito general AX,BX,CX,DX , tenemos otros que apuntan a los segmentos dentro de la memoria SS,CS,DS... (Para más información teneis el libro Arquitectura de Computadores de Hennessy y Patterson). Además de los registros, para guardar datos tenemos la memoria (la memoria recuerda cosas....).
De los registros tenemos uno de suma importania, IP o Instruction Pointer o Program Counter. Este registro se encarga de ir apuntando la siguiente dirección de memoria , como el código suelen ser saltos a funciones, condiciones, rutinas ... Pues necesitamos un registro que guarde la siguiente dirección de memoria a ejecutar. Bien en el programa de ejemplo del otro día hacíamos una llamada a una función, eso en ensamblador se convierte en un "Call", el cual es una de las pocas funciones que pueden modificar IP, al volver de la función el programa debe saber donde volver, por tanto guarda en una memoria específica (llamada la Pila a partir de ahora) el valor de IP antes de llamar a la función. En la pila se guardan los argumentos de las funciones, IP, variables locales... Esto permite la recursividad en programación.
Veamos un ejemplo de la llamada a la función del otro día en ensamblador (la cual tenía un argumento):
push arg ;mete argumento en la pila
call func ;llama a la funcion mete valor IP en la pila
Bien una vez dentro de la función debemos reservar como una "Pila" propia de la función para las variables de la función, esto es lo que se llama marco de pila, tenemos un registro llamado BS que apuntará al principio de esa pila, y tenemos SP que apunta siempre al final de nuestra pila. Pues un marco de pila se crea algo como así:
push bs ;guardamos el valor de bs (para no cargarnoslo), luego lo recuperaremos
mov bs, sp ; metemos el valor de sp, en bs (ya tenemos la base de nuestra pila)
sub sp, X ;restamos X al valor de sp, asi agrandamos nuestra marco de pila
Os preguntareis ¿Por qué restas X, en vez de sumar? si lo que queremos es agrandar, bien la pila va desde las direcciones de memoria más altas, a las más bajitas, por tanto para crecer, tenemos que restar (Imaginaos la pila como un hombre algo rata, nos deja unas direcciones lejos de la dirección más baja de la pila, una alta, y para reservar memoria en la pila, tenemos que quitarle direcciones, pues restamos).
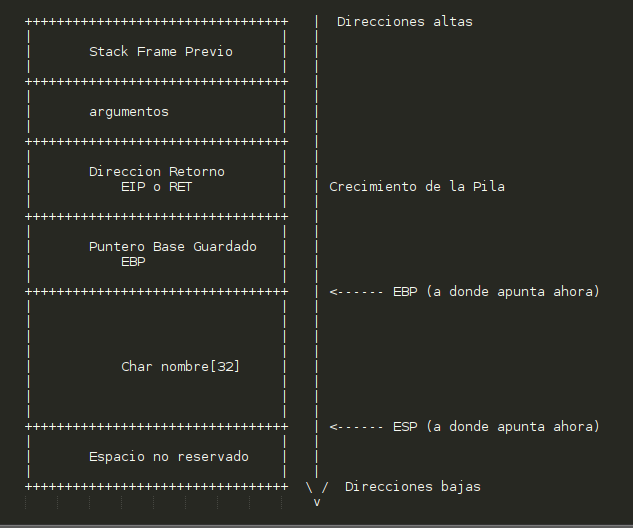
Bien pues veamos un dibujo de como quedaría la pila, y a donde apuntarían ahora BS y SP.
(me he currao el dibujito ¿no?)
Bueno vemos que en los registros antes ponemos una 'E', esto significa que es un procesador de 32 bits, y en lugar de guardar 16 bits en el registro, guardamos 32 (un sistema operativo de 32 bits, sus direcciones tienen 32 bits).
Como vemos arriba del todo (las direcciones más altas) tenemos un marco de pila de otra función (por ejemplo main), y seguido metemos unos argumentos, luego la dirección a la que volveremos después, seguido el valor de BP para volver a cogerlo al acabar la función, vemos que EBP, al realizar el
mov ebp,esp , ahora ebp apunta a donde se puede ver, seguido se haría
sub esp,32 , para guardar la variable nombre, por tanto ahora esp apunta al final del buffer nombre.
Ahora viene lo siguiente la...
¿Por qué? , por que mientras que el buffer Nombre, se reserva para abajo, crece para arriba, y nosotros al meter un gritón de 'A's, llenabamos el buffer, luego llenabamos el valor guardado de EBP y finalmente el valor guardado de EIP, por tanto al acabar la función en donde estaba el valor de EIP ahora hay "AAAA", y el procesador intentaba saltar a la dirección "0x41414141", la cual no está mapeada en nuestras direcciones de memoria.
Y por eso el programa petaba.
Ahora vamos una vez acaba la teoría, con la parte práctica.
¿Qué vamos a aprender?
- Encontrar manualmente cuantos bytes necesitamos para petar el programa.
- Encontrar automáticamente cuantos bytes necesitamos para petar el programa.
- Explotar este fallo para conseguir una shell.
1. Encontrar manualmente cuantos bytes necesitamos para petar el programa
Bien para realizar esto, vamos a utilizar el debugger: edb-debugger (Descargable aquí:
https://github.com/eteran/edb-debugger ).
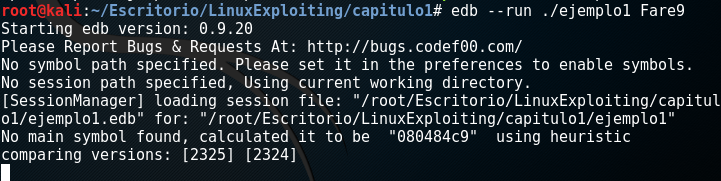
Para empezar vamos a ejecutar nuestro programa con este debugger y vamos a meter como argumento por ejemplo nuestro nombre y ver como se ejecuta:
Bien ahora iremos al programa edb-debugger a ver que nos encontramos:

En el centro tendremos bien en grandote tenemos el códigooooo (de momento pasad de este, por que no nos vale para nada).
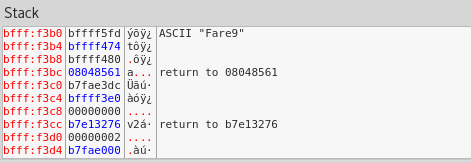
Tenemos la pila, donde vemos por ejemplo los argumentos de char argv[], el primero es ./ejemplo1 (nombre del programa) y el segundo es Fare9 (nombre).
Y finalmente tenemos los registros, los 4 primeros son registros de proposito general, tenemos EBP, ESP que apunta justo a la cima de nuestra pila (imagen de arriba de la Stack), ESI y EDI (ahora mismo no nos interesan mucho). Y finalmente uno que nos interesa mucho EIP, el cual vemos que está apuntando al principio del código que tenemos (imagen de arriba de código).
Como vemos está apuntando ahora mismo a una librería, todavía no es nuestro código. Por tanto para establecer todo al principio de nuestro main ejecutaremos:
F9 .
Ahora tenemos otro código diferente y los registros también han cambiado su valor (en concreto EIP ahora apunta a la primera instrucción de nuestro código). Vamos a intentar reconocer un poco lo que se está haciendo. Lo primero que vemos es un lea (siglas de load effective address) a insertar un valor en ecx, ese valor es [esp+4]. Esto en ensamblador es una forma sencilla de meter en ecx el valor de esp + 4. Luego se realiza una operación lógica and, seguido de un push, el cual vale para insertar datos en la pila como hace push con [ecx-4] es coge el valor de ecx restale 4 y accede a la dirección de memoria que es igual a ese valor de la resta, y lo metes en la pila. Bien no es un curso de ensamblador para cualquier cosa podéis ir a las referencias de abajo.
Vamos a algo más clave, un cmp (código para compare), compara un valor que guarda la dirección de memoria guardada en eax, con 2 (igual que hacíamos en nuestro programa) estamos comparando argc con 2, en caso de ser iguales (jz [jump if zero] es igual a je [jump if equal]) y vemos que si son iguales salta a0x0804501 (un poquito más abajo).
Para poder avanzar en edb debugger tenéis
F7 y
F8 , la diferencia entre ambos es que F8 si encuentra un call (o función) la ejecuta y pasa por encima, y F7 NO.
Pues ejecutemos hasta realizar el salto:
Bien ya estamos después del salto, vemos que tenemos 3 instrucciones que lo que hacen es buscar el primer argumento argv[1], el cual es nuestro nombre, antes del call tenemos push eax, que lo que hace es meter la dirección donde se encuentra "Fare9" en la pila, para finalmente llamar a Func(args).
Si vamos observando la pila veremos que al llegar al call, lo que tendremos es Fare9.
Bien, ahora realizaremos el call, y como os he contado antes, se debe meter la dirección siguiente al call ( 0804:8512 ), para entrar al call avanzamos con
F7 .
Como vemos en la cima de la pila, se ha guardado la dirección de retorno.
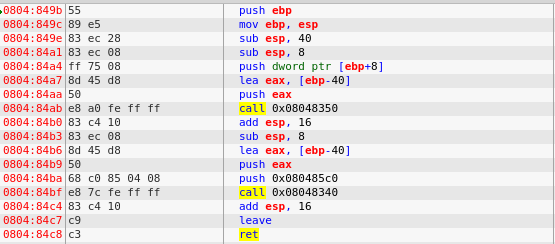
Y vamos a ver el código que tenemos:
Vamos a ver las 3 primeras lineas, estas crean como os conté antes el "Marco de Pila", como vemos reserva en un principio 40 bytes, pasaremos del
sub esp,8 . Lo siguiente es la llamada a la función strcpy(Nombre,arg) que teníamos en el código original.
En ensamblador al llamar a una función tenemos que meterle en la pila sus argumentos, los cuales los meteremos de derecha a izquierda, por tanto al meter [ebp+8] metemos el argumento que pasamos antes ("Fare9"), con
lea eax,[ebp-40] , estamos haciendo que eax apunte al principio del buffer (40 bytes más abajo), seguido lo metemos en la pila y finalmente llamamos a
strcpy. Ahí es donde vendrá nuestra oportunidad de insertar datos y datos. Iremos llamando ahora con F8 hasta llegar al call:
Vemos que primero se metió "Fare9" (la dirección de esa cadena), seguido del lugar de la pila donde se copiará BYTE A BYTE hasta encontrar un \0. Ejecutaremos y veremos la dirección de la pila bffff380:
Bien entonces, vemos que en bffff380 (como se indicó arriba) se ha copiado la cadena Fare9, y abajo del todo en bffff3ac, tenemos la dirección de retorno a donde volveremos después de finalizar Func(), cojamos nuestra calculadora de programador y restemos bffff3ac - bfff:f380. La respuesta es 2C (el sentido de la vida...) bueno esto es el valor hexadecimal de: 44. Que es el número de bytes que metiamos antes de petar el programa, tras insertar 44, los siguientes petarán el programa, pues como veis ahora GRÁFICAMENTE, estamos modificando el valor de retorno.
Hemos aprendido entonces como ver cuantos bytes necesitabamos para petar el programa manualmente.
2. Encontrar automáticamente cuantos bytes necesitamos para petar el programa.
ahora seremos más rápidos, sabemos que con gdb al ejecutar el programa y petarlo con tropecientas 'A's, nos decía gdb, el programa ha petado por intentar acceder a la dirección 0x41414141, bien¿ y si metemos "AAAABBBBCCCCDDDDEEEE...."?, depende de con qué sobreescribamos EIP nos dirá que ha petado con otra letra o conjunto de ellas, y después pues calcular "si he metido tropecientas letras en la cadena, y ha petado en la 'E', y cada letra eran 4 veces repetidas..." Bueno si no quereis hacer calculos podéis usar los programas "Pattern_create.rb" y "Pattern_offset.rb" de Metasploit los cuales uno te genera una cadena de caracteres aleatorios, y el otro le dices la cadena y el hexadecimal (creo) de dónde ha petado, y te dice bytes para petar el programa. Peeeero, si queréis un poco que pueda seguir con estas entradas, os pido useis mi versión
PatternPetater . Un script en python que te hace las dos cosas a la vez.
En principio vamos a ejecutar el patternpetater, para ello : python randomGenerator.py .
Primero lo ejecuté sin argumentos y después con 128, ha generado una cadena aleatoria de 128 bytes, ahora ejecutaremos el programa ejemplo1 con gdb, seguidamente haremos un RUN y copiamos y pegamos la cadena anterior, lo cual dará un fallo:
Primero llamamos a gdb, seguido dentro de gdb ejecutamos run junto con la cadena que generó PatternPetatter, finalmente tuvimos un error con lo de la dirección : 0x77526846 (se cortó en la imagen). Bien copiamos esta cadena y la pegamos en PatternPetater, que estaba esperando por nosotros:
Como vemos PatternPetater, nos dice que 44 es el máximo de bytes antes de petar el programa, pues el String que causó el error fue FhRw (el cual está dentro de la cadena antes generada).
Bien con esto sacamos automáticamente cuantos bytes tenemos hasta petar el programa y sobreescribir EIP, esto nos será importante para saber que payload (lo explicaré en la siguiente entrega), podemos insertar, ya que 44 bytes no es mucho, por ejemplo un Meterpreter no podríamos.
3. Explotar este fallo para conseguir una shell.
Ahora vamos a crear un primer exploit en python, con lo cual uniremos un payload que se mostrará en el código, junto con purrelez que tenemos que meter para llegar a 44 bytes, más la dirección de retorno que guardaremos en donde estaba EIP, que será el principio del buffer, para que se ejecute nuestro código que insertamos:
Aquí tenemos el shellcode, los nops son código que el procesador ejecuta sin hacer nada los cuales los pondremos antes del shellcode, para cuando el procesador salte al principio del buffer, ejecute un NOP y siga ejecutando hasta encontrar el shellcode. Como veis, la dirección de retorno es diferente a la que sacamos antes, esto puede cambiar por eso tenemos la última linea (ahora comentada), que nos abriría el debugger, para sacar la dirección a la que tenemos que saltar. Al ejecutar este exploit debemos obtener una shell de comandos:
Como vemos, al ejecutar el exploit, se llamó al printf que teníamos después de strcpy, hizo caplof, y por arte de magia (ir al gif de magic), nos devolvió una SHELL, para poder ejecutar nuestras cosas de Hackers y todo eso, por ejemplo podríamos dejar una shell a la escucha con netcat o aún mejor ncat cifrada con clave pública.
--------------------------------------------------------FIN
Como vemos hoy hemos aprendido mucho, mucho. Vimos como sacar manualmente el número de bytes para petar el programa, vimos como utilizar herramientas para conseguir esto, y además creamos un primer exploit (no digais que Fare9 no enseña cosas pa' aburrir) .
Ya sabeis que podeis encontrarme en Twitter ( como Fare9 ), o podeis escribir en comentarios e intentaré responderos lo antes posible.
Nos vemos en el siguiente "de 0 a exploiting"
Referencias:
Más información en los apuntes de laboratorio de este hombre:
http://atc2.aut.uah.es/~rico/docencia.htm















































{kind=link}
{kind=link}